Mennesker og tilfældighed
Inspireret af denne video fra numberphile satte jeg mig for at undersøge om mennesker virkeligt er så dårlige tilfældighedsgeneratorer som de påstår.
Påstanden er at hvis man beder en masse tilfældige mennesker om at nævne et tilfældigt tal mellem 1 og 10, så vælger ca 45% af alle mennesker 7 som deres “tilfældige” tal. Jeg tænkte dog at jeg ligeså godt kunne få noget smæk for skillingen, og se om der måske også var nogle flere/andre tendenser, så jeg designede et lynhurtigt google-spørgeskema der bad om et tal mellem 1 og 10, ét mellem 1 og 100 og ét mellem 1 og 1000.
Jeg fik 70 svar på et par uger (og tak til alle der bidrog!), og det var nok til lidt indledende fisketur i data, men først lidt teori og baggrund.
Hvis menneskene der svarer virkelig ER gode tilfældighedsgeneratorer, og der er nok der har svaret, så forventer jeg at et histogram over svarfrekvenser kommer til at se omtrent således ud:
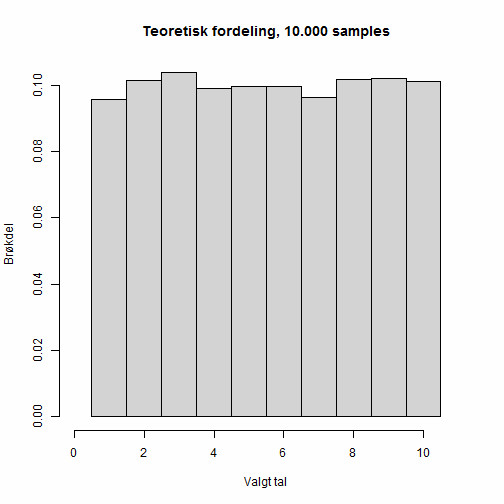
Altså at alle tal er ligeligt repræsenteret, men ikke nødvendigvis rammer præcis 10%. Ovenstående er en simuleret fordeling med 10.000 tilfædlige tal, og den er derfor ret tæt på det ideelle tilfælde. Jo færre prøver / deltagere vi har, jo mere kan vi afvige fra det ideelle tilfælde, uden det nødvendigvis betyder noget. Som eksempel har jeg foretaget 4 simulationer, hvor der er udtrukket 70 tilfældige tal i intervallet 1 til 10, og det gav følgende resultat:
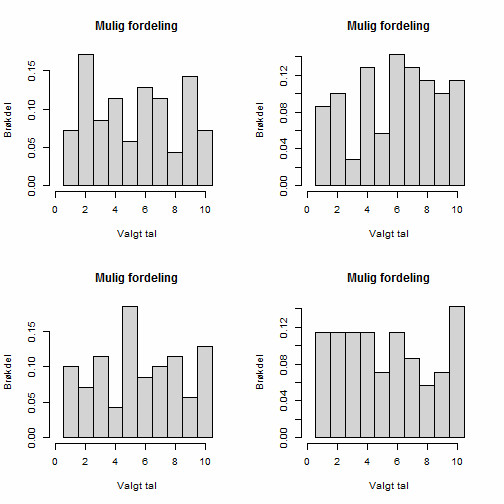
Disse ser ikke umiddelbart særligt jævnt fordelte ud, men ikke desto mindre består de en statistisk test for ensartethed. Netop fordi der er så få målepunkter skal der kun flyttes ganske få tal fra én værdi til en anden før det kommer til at se meget ujævnt ud, uden det nødvendigvis har en betydning for om tallene kan antages at være udtrukket tilfældigt.
Indsamlede data
De data jeg fik ind fordelte sig således mellem 1 og 10:
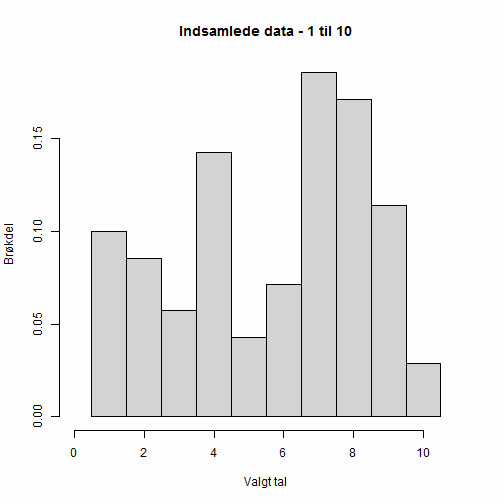
Dette ser ikke umiddelbart meget mere skævt ud end nogle af eksemplerne ovenfor, men hvis man laver den relevante statistiske test (chi i anden) ser man at hvis tallene virkeligt var helt tilfældigt valgt, så er der kun ca 3,5% sandsynlighed for at at resultatet vil fordele sig som det gør. Normalt anvender man 5% som grænseværdi for hvornår noget er signifikant, så i dette tilfælde kan vi altså konkludere at vores data sandsynligvis ikke kommer fra en jævn fordeling, og altså implicit konkludere at mennesker er dårlige til at generere tilfældige tal.
Vi ser dog også at der er langt op til de lovede 45% der vælger 7 - det bedste estimat ud fra disse data er at et eller andet sted imellem 10% og 30% af de adspurgte vil vælge 7, hvilket jo også er væsentlig flere end man ville forvente ved en jævn fordeling.
En anden påstand der bliver fremsat i videon er at “lige tal virker mindre tilfældige” - hvis dette er sandt må frekvensen af disse afvige signifikant fra 0.5, men det kan ikke underbygges af data fra undersøgelsen - faktisk er der ret præcist lige mange lige og ulige svar i puljen.
De øvrige data - altså dem fra 1 til 100 og 1 til 1000 er det ikke muligt at sige noget fornuftigt om ud fra et så lille dataset. Der var ikke nogle umiddelbart interessante tendenser at spore, så jeg undlod at torturere datasættet yderligere - det skulle jo nødig ende med at tilstå noget det ikke var skyldigt i.
Konklusioner og Opsummering
Mennesker er ikke ret gode tilfældighedsgeneratorer.
De lader til at have en forkærlighed for 7, om end den ikke er helt så stor som forventet ud fra oplægget. Til gengæld er det lige sandsynligt at de vælger lige eller ulige tal.
Dette reducerer altså groft sagt mængden af tilfældighed i et tal mellem 1 og 10 fra 3–4 bit og ned til ~1 bit - man kan med andre ord lige så godt slå plat eller krone. Hvis man bliver bedt om at finde på tilfældige tal i forskellige intervaller samtidig, lader der ikke til at være nogen tendens til at ligge generelt højt eller lavt.
Noter
- Hvis man virkelig skal have ægte tilfældighed så anbefaler jeg http://www.random.org, der også har et fint API og en pakke til R.
- Der var ikke rigtig data nok til at lave rigtig hardcore studier af tilfældighed og tendens, som man fx gør med “dieharder” programpakken.
- Tilfældighed er noget skrald at skulle definere og kvantificere!
- Rådata ligger i min dropbox, hvis du selv skulle have fået lyst til at lege.
- Det samme gør mit originale R-markdown-dokument, hvis nogen skulle have lyst til at se koden. Det er skrevet i RStudio, som jeg også anbefaler varmt.
- Hatteviften til Yihui for knitr–pakken
\Worm